I Tested RAG and Long Context on Real Docs — Here's What the Numbers Say
I tested RAG and Long Context approaches against real open-source documentation using local LLMs on consumer hardware. Here's what I found.
I’ve been working with RAG and long-context approaches for a while, but I wanted to test them side by side on real data — confirm the trade-offs in actual numbers rather than relying on intuition.
TL;DR
- RAG is 42x cheaper on tokens and the fastest approach overall — use it for repeated queries against large documentation
- Long Context gives more complete answers on hard questions where the answer is scattered across many sections, but at much higher compute cost
- Accuracy depends on question type, not approach — for focused questions, all three approaches (including no context at all) perform similarly
- Larger models help accuracy but don’t change the trade-off — the RAG vs Long Context pattern holds across 7B, 14B, and 30B+ models
The Problem
LLMs know a lot about popular frameworks from their training data. But training knowledge gets stale — APIs change, new features ship, docs get rewritten. If you want an LLM to answer questions about documentation accurately, you need to get that data into the model at query time. Two approaches:
- RAG (Retrieval Augmented Generation) — chunk the docs, embed them, store in a vector database, retrieve relevant pieces per query
- Long Context — put the entire documentation into the prompt, let the model’s attention mechanism find the answer
I tested both against FastAPI documentation (~117K tokens from tutorial, advanced, and reference sections) using two local LLMs served via Ollama with LiteLLM as a client.
Setup
- Hardware: Lenovo ThinkPad — Intel 12th Gen CPU, 64 GB RAM, NVIDIA RTX A2000 8GB Laptop GPU
- Models: Qwen2.5-7B-Instruct and Qwen2.5-14B-Instruct (Q4_K_M quantization)
- Embedding: nomic-embed-text (768 dimensions) for RAG chunking
- Inference: Ollama with flash attention, GPU + CPU offload for the 14B model
- RAG config: 512-token chunks, 50-token overlap, top-5 retrieval via ChromaDB
Test Results
I ran 8 questions per model — 4 focused (single fact, cross-document reasoning) and 4 hard (aggregation, completeness, multi-section). Here’s what I found:
- Long Context uses 42x more tokens. Long Context used ~33K tokens per query. RAG used ~800. For repeated queries against the same documentation, that’s a massive difference in compute cost.
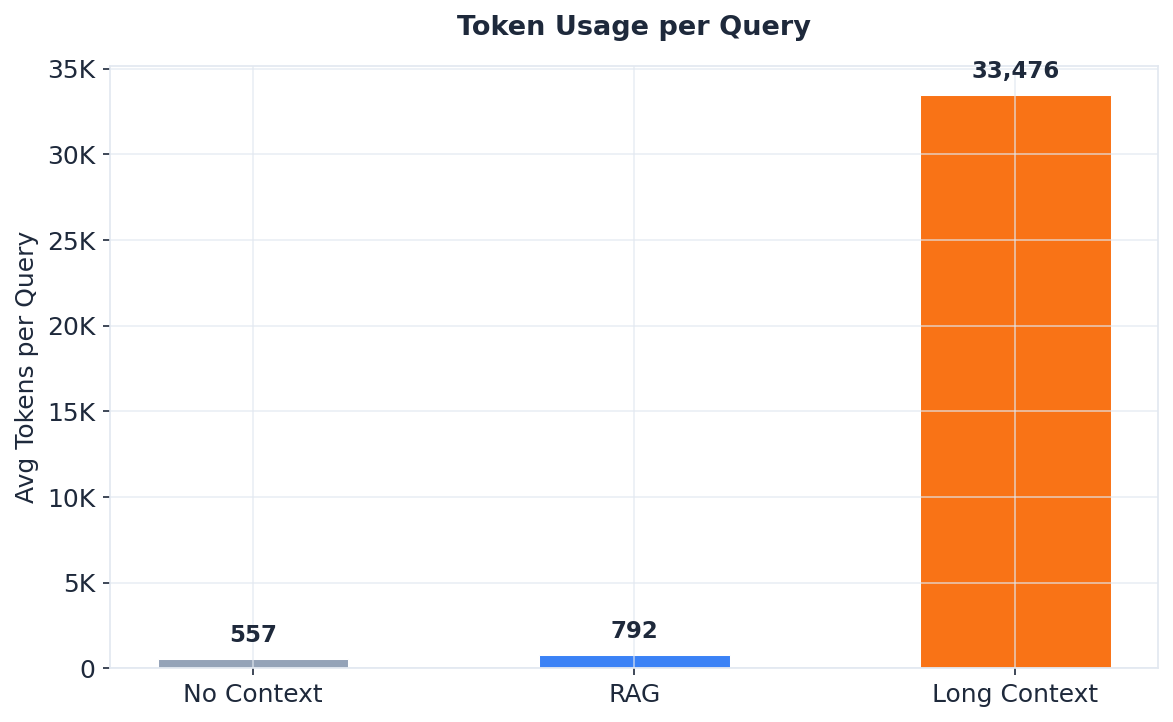
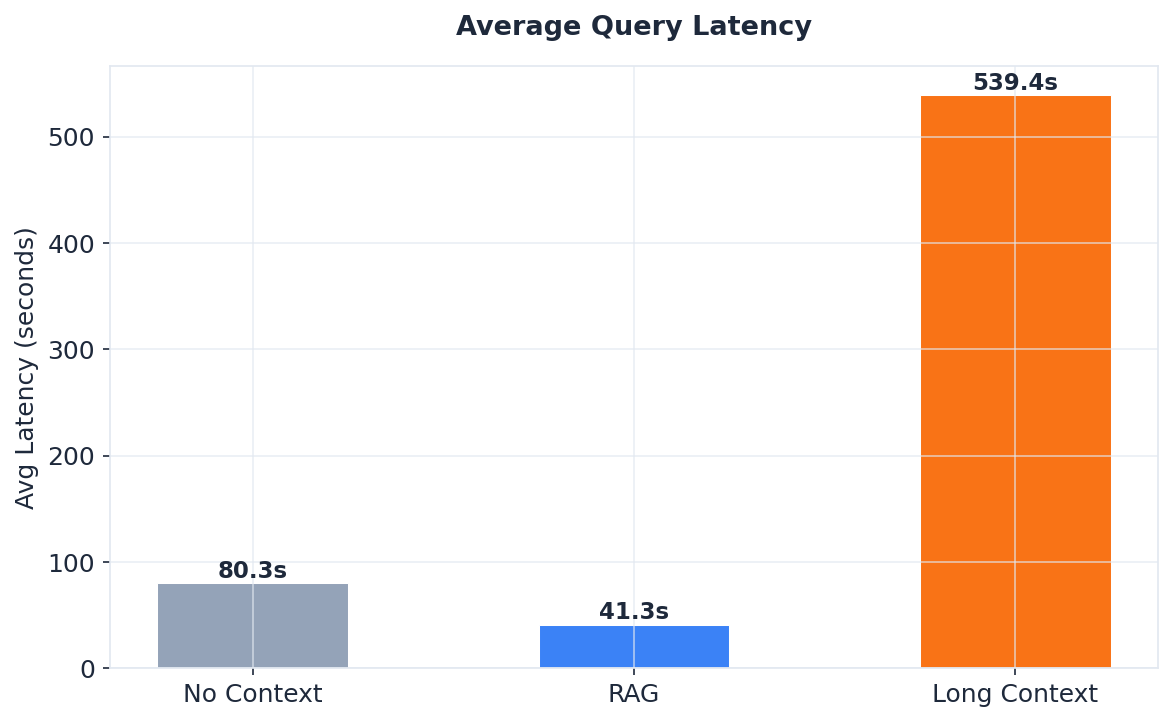
- RAG is the fastest approach. RAG averaged 41 seconds per query. No Context averaged 80 seconds (models generate longer answers without focused context). Long Context averaged 539 seconds (~9 minutes) — dominated by prompt processing on consumer GPU.
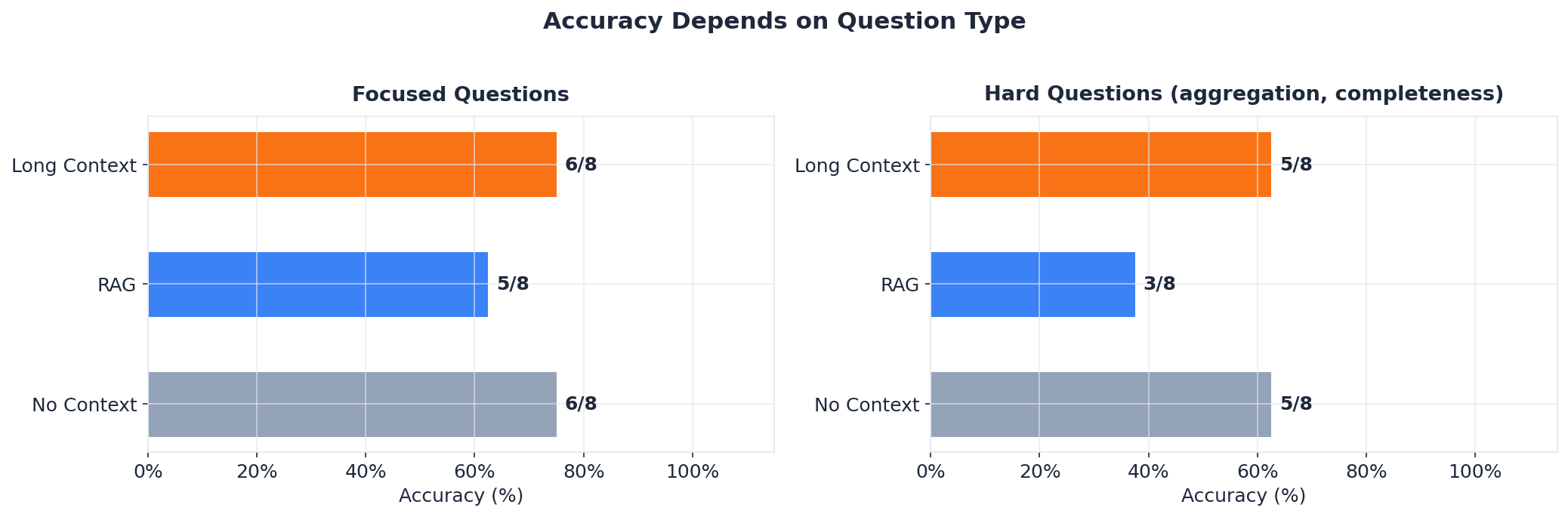
- RAG struggles with hard questions. When the answer is scattered across many sections — “list all parameter types” or “list all decorator parameters” — top-5 chunk retrieval can’t gather enough. RAG scored 3/8 on hard questions. Long Context and No Context both scored 5/8.
- Focused questions work everywhere. For questions where the answer lives in 1-2 places, all approaches performed similarly (5-6/8). FastAPI is well-documented and models know it from training data.
- Local inference is slow but viable. The 7B model averaged 2.5 minutes per long-context query. The 14B model averaged 15 minutes — usable for testing, not for production.
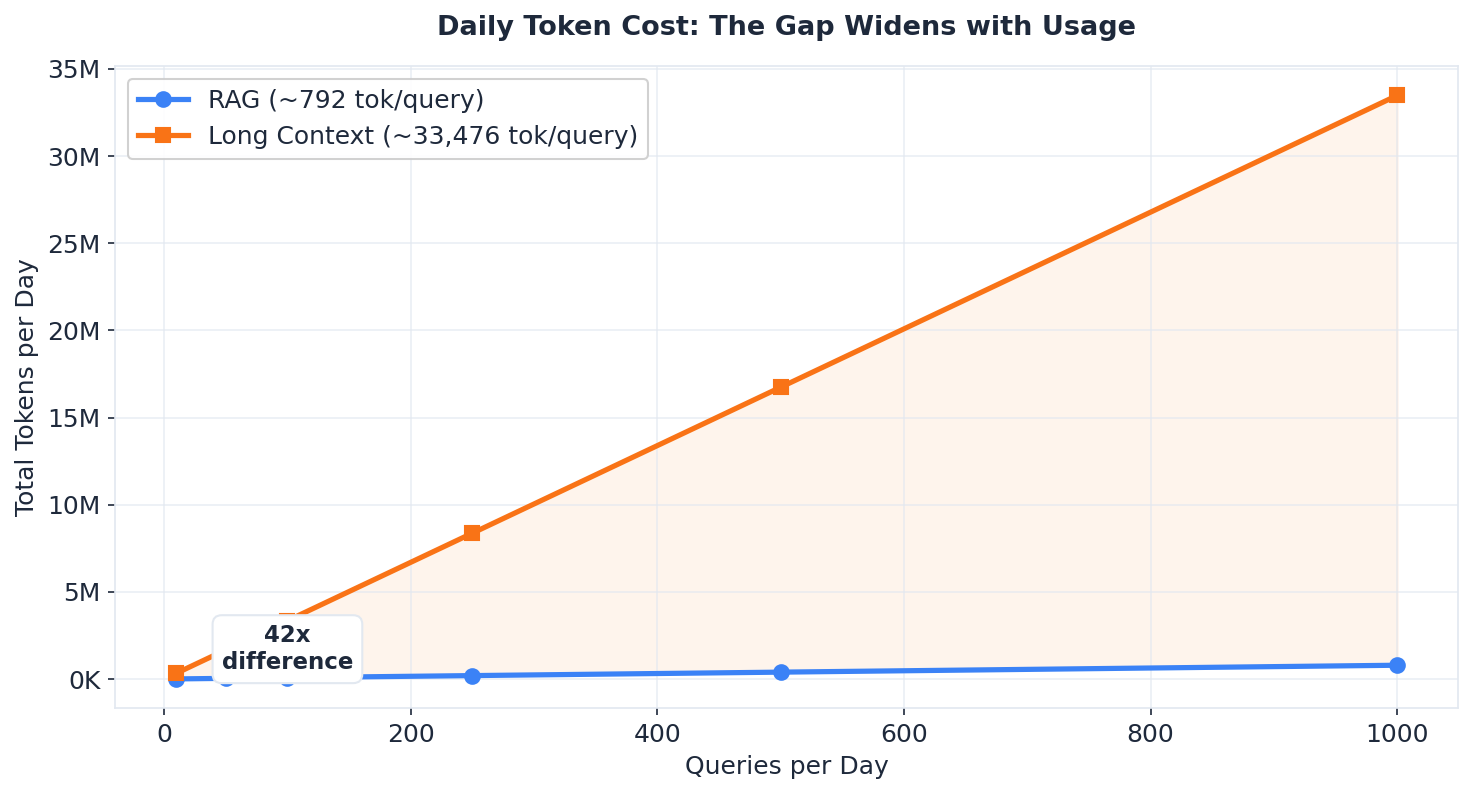
- The cost gap widens with usage. At 100 queries/day, Long Context burns ~3.3M tokens vs RAG’s ~79K — a 42x difference that only grows with scale.
The complete test suite, all results, and methodology are in the rag-vs-long-context repository.
Running This Locally
The entire test runs on consumer hardware. The key constraint is VRAM — with 8 GB, the 7B model fits entirely on GPU while the 14B splits across GPU and CPU. Ollama handles the offloading automatically. Flash attention (OLLAMA_FLASH_ATTENTION=1) is critical for keeping KV cache memory manageable.
One important caveat: Ollama capped the effective context at ~32K tokens (not the full 117K) due to VRAM constraints. This means the long-context results reflect a truncated view of the documentation. With more VRAM or a cloud GPU, the full 117K context would be feasible.
What Changes with Larger Models and More VRAM
I also ran the same tests with 30B+ parameter models on hardware with enough VRAM to fit the full 117K token context. The core conclusions don’t change, but the numbers shift:
- Latency drops dramatically. RAG averaged 11 seconds per query (vs 41s locally). Long Context averaged 44 seconds (vs 539s locally). Dedicated GPU inference is 4-12x faster than CPU-offloaded laptop inference.
- The token gap gets worse. With full 117K context, Long Context burns ~116K tokens per query — a 94x difference over RAG’s ~1,200. On local hardware, the truncated context made this gap look smaller (42x) than it actually is.
- Accuracy improves across the board. Larger models scored 8/8 on focused questions for all approaches. On hard questions, Long Context scored 6/8 (vs 5/8 locally) and RAG scored 4/8 (vs 3/8 locally). More parameters help, but the relative pattern — RAG weakest on scattered-answer questions — stays the same.
- The context window wall is real. The full FastAPI documentation at ~363K tokens exceeded even 256K context windows. Only RAG works at that scale, regardless of hardware.
The takeaway: model size and VRAM budget affect the absolute numbers, but not the trade-off. RAG is still cheaper and faster. Long Context is still more complete. The decision depends on your question type and query volume, not your hardware.
Summary
Use both. Match the approach to the question type.
For popular, well-documented frameworks, models already know the basics from training data. Context injection matters most for specifics, freshness, and completeness — the details that change between releases.
RAG is the clear winner for repeated queries against large documentation — it’s faster, cheaper, and scales beyond any context window. Long Context is simpler for one-off analysis of bounded documents, but the compute cost scales linearly with document size and query volume.